第一章:基础
计算机如何构建
CPU负责所有计算
计算机既然称为「计算机」,总要有负责计算的元件吧。计算机的中央处理器(CPU)就是负责所有的计算的元件,它其实很「傻瓜」,只会一条一条机械执行命令。
CPU执行的“指令”只是二进制数据:一个或两个字节表示正在运行的指令(操作码),后面是运行指令所需的任何数据。机器码只不过是一系列这样的二进制指令。
正常的人类看0101这样的二进制都会眼花吧。因此,汇编语言出现了!
汇编是一种很有用的语法,用于阅读和编写机器代码,这比原始位更容易被人类读取和写入;它总是被编译为CPU知道如何读取的二进制文件,如下图:

小知识
最早的大规模生产CPU是Intel 4004。
数据存哪里
上面提到,CPU的指令表现为二进制数据,其实就是一条条的操作码和数据。那这个二进制数据总有地方存吧。存哪里呢?对,就在RAM(Random Access Memory,随机存取存储器)中。
RAM是计算机的主内存库,一个大型多用途空间,存储计算机上运行的程序所使用的所有数据。这包括程序代码本身以及操作系统核心的代码。CPU总是直接从RAM中读取机器代码,如果代码没有加载到RAM中,则无法运行。
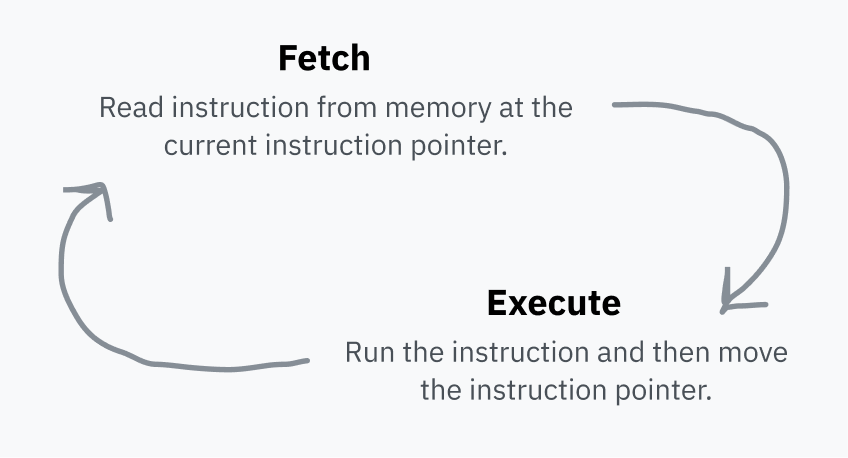
CPU存储一个指令指针,该指针指向RAM中它将获取下一条指令的位置。在执行每个指令之后,CPU移动指针并重复。这就是 Fetch—Execute 循环,如下图:
寄存器加速CPU计算
指令指针存储在寄存器中。寄存器是小的存储桶,对于CPU读取和写入来说非常快。每个CPU架构都有一组固定的寄存器,用于从计算期间存储临时值到配置处理器的所有操作。
有些寄存器可以直接从机器代码访问,如前面图中的 ebx。但其他寄存器仅由CPU内部使用,但通常可以使用专用指令进行更新或读取。一个例子是指令指针,它不能直接读取,但可以用例如跳转指令来更新。
处理器其实「很傻很天真」
CPU有一个超级「傻瓜」的世界观:它只看到当前指令指针和一些内部状态。进程完全是操作系统级别的抽象概念,CPU本身并不直接理解or追踪进程。
既然CPU这么「傻」,但计算机却能处理很多高级的计算,看着很矛盾对吧?作者抽象了3个问题:
- 如果CPU不知道多进程并且只按顺序执行指令,为什么它不会在运行的程序中卡住?如何能同时运行多个程序?
- 如果程序直接在CPU上运行,而CPU可以直接访问RAM,为什么代码不能访问其他进程的内存?
- 是什么机制阻止每个进程运行任何指令并对你的电脑做任何事情?
小纸条
问题1的答案是时间片(分时),问题2和3的答案涉及到了系统调用/内核和用户态。
“内核模式”和“用户模式”
处理器计算过程中总要和资源(分配内存、磁盘I/O、网络I/O)打交道。如果所有程序都直接操作这些资源,那操作系统还稳定吗?
显而易见,答案是不稳定。程序A要删除某个资源,程序B却要读取这个资源,不就乱套了吗?
怎么办?敏感资源必须是自己人才可靠,对吧?这个可靠的「自己人」就是「内核模式」,对应地,被认为「不可靠的」的就是「用户模式」。
在内核模式下,什么都可以做,因为是「自己人」嘛,因此CPU被允许执行任何支持的指令和访问任何内存。
在用户模式下,就惨了,只允许执行指令的子集,I/O和内存访问都受到限制,许多CPU设置也被锁定了。

小贴士
通常,内核和驱动程序运行在内核模式下,而应用程序运行在用户模式下。
系统调用是两种模式沟通的桥梁
理解系统调用
「内核模式」和「用户模式」两种模式统治了CPU世界。那么,运行在「用户模式」下的应用程序要操作资源怎么办,比如一个程序要读取本地文件?
答案是「外围」的应用程序求助于「内核」,将程序控制权交给「内核」(这个过程称之为系统调用),「内核」操作完资源后,再将控制权交给应用程序,这就完成了对资源的操作。可以看出,系统调用是两种模式沟通的桥梁。
编程层面理解
如果你曾经写过与操作系统交互的代码,你可能会认识到像 open 、 read 、 fork 和 exit 这样的函数。在几个抽象层之下,这些函数都使用系统调用来请求操作系统的帮助。系统调用是一个特殊的过程,它让程序开始从用户空间到内核空间的转换,从程序代码跳转到操作系统代码。
思考
上面这个过程,不就是 「服务端 -- 客户端」模式吗?内核提供服务,应用程序调用服务。那么,为什么不是多个微服务之间那种「请求-响应」模式呢(比如HTTP这种)?答案是效率!系统调用效率高很多。
软件中断控制两种模式转移
用户空间到内核空间的控制转移是使用一个称为【软件中断】的处理器特性来完成的:
- 启动过程中,操作系统会将一个称为中断向量表的表存储在RAM中,并将其注册到CPU。中断向量表将中断号映射到处理程序代码指针。
- 然后,用户空间程序可以使用类似INT这样的指令,告诉处理器在中断向量表中查找指定的中断号码,切换到内核模式,然后将指令指针跳转到存储在中断向量表中的内存地址。
当这个内核代码完成时,它使用一个类似于IRET的指令来告诉CPU切换回用户模式,并将指令指针返回到触发中断时的位置。
通过调用共享库函数使用系统调用
关于系统调用:
- 用户模式程序不能直接访问I/O或内存。他们必须请求操作系统帮助与外部世界交互。
- 程序可以使用像INT和IRET这样的特殊机器代码指令将控制权委托给操作系统。
- 程序不能直接切换权限级别;软件中断是安全的,因为处理器已经被操作系统预先配置好了跳转到操作系统代码的位置。中断向量表只能从内核模式配置。
- 请求中断-中断触发(控制权回到操作系统)-执行(内核代码执行)-返回控制权。
这种叫做软件中断,和硬件中断不一样,不涉及到完整的上下文切换,CPU仍然在处理程序的请求,只是在操作系统内核的上下文中处理。
知识拓展:硬件中断
硬件中断是由硬件设备发送的信号,用来中断CPU当前的执行流程,请求CPU处理特定的事件。硬件中断使得CPU能够响应外部事件,如键盘敲击、网络数据包到达等。
操作系统在这些中断之上提供了一个抽象层,基于以下原因:
- 系统调用在不同设备之间的差异意味着程序员自己为每个程序实现系统调用是非常不切实际的。
- 这也意味着操作系统不能改变他们的中断处理,因为担心破坏每个使用旧系统编写的程序。
- 最后,我们通常不再使用原始汇编语言编写程序--不能指望程序员在任何时候想要读取文件或分配内存时都使用汇编语言。
可重用的高级库函数包装了必要的汇编指令,在类Unix系统上由libc提供,在Windows上是一个名为ntdll.dll的库的一部分。调用这些库函数本身不会导致切换到内核模式,它们只是标准函数调用。在库内部,汇编代码实际上将控制权转移到内核,并且比包装库子例程更依赖于平台。
也就是说,编程时对两种模式其实是「无感」的。编程只需要调用操作系统对软件中断所做的抽象库函数即可。比如,当你从运行在类Unix系统上的C调用 exit(1) 时,该函数在内部运行机器码以触发中断,在将系统调用的操作码和参数放入正确的寄存器/堆栈/任何东西之后。简直泰裤辣!
知识延伸
作者提到了vDSOs(the virtual ELF dynamic shared object,虚拟ELF动态共享对象概述)技术,这是一种系统调用使用的替代技术,推荐读者进一步了解。
总结
处理器在一个
Fetch—Execute的无限循环中,这里不存在任何操作系统或程序概念。处理器的模式通常存储在寄存器中,该模式决定了执行哪些指令。操作系统代码运行在内核模式,在运行程序的时候切换到用户模式。执行二进制程序时,操作系统切换到用户模式,处理器的指针指向内存的接入点。因为程序只有用户模式,要想与外界交互就必须通过操作系统,而系统调用就是程序与外界交互的方式。
程序通过调用共享库函数唤起这些程序调用。这些包装机器码用于软件中断或特定于体系结构的系统调用指令,这些系统调用指令将控制权转移到操作系统内核和模式切换代码并返回程序码。